Czasem zachodzi potrzeba pracy przez krótki czas z zasobami, do których nie mamy na co dzień dostępu. Coś zachowuje się dziwnie, dostajemy tymczasowy dostęp do jakiegoś API, żeby móc wysyłać zapytania z naszego laptopa i szybciej dojść, co poprawić. Mamy jedno tajne hasło, albo coś bardziej rozbudowanego, na przykład zestaw 7 różnych parametrów: client ID, client secret, jakiś token, jakiś specjalny URL i inne cuda niewidy.
Jak wygodnie pracować w takich warunkach?
W artykule krótko opowiem o jednym z rozwiązań: plikach .env . Jaki mają format, jak z nich korzystać (w terminalu i IDE, na przykład odpalając testy albo inne taski z wykorzystaniem Gradle’a), czemu są wygodne.
Spis treści
Na piechotę
Co zrobić z hasłami, gdy nie mamy żadnego pomysłu?
Na potrzeby przykładu moim poleceniem używających tajnych kluczy będzie curl:
curl -H 'ClientId: client1' -H 'ClientSecret: 84dac9e' http://secret.com
To najgorsze rozwiązanie ze wszystkich. Mieszamy istotne rzeczy (URL serwera) ze szczegółami (tajny klucz), nie da się tego przeczytać, polecenie pewnie zawinie się na kilka wierszy. Nawigacja klawiaturą, żeby coś zmienić będzie niewygodna. Gdy odpalimy takie polecenie, w historii poleceń (~/.zsh_history) zostaną tajne dane. Do tego jeśli tajny klucz to bardzo długi string, jest szansa, że wyszukując polecenia (Ctrl+R) dostaniemy w podpowiedzi przypadkowe trafienie we fragment klucza zamiast w sensowne polecenie (wpisujemy da licząc na znalezienie date -Is a dostajemy zamiast tego curla z 84dac9e).
Trochę lepiej:
% CLIENT_ID=client1 % CLIENT_SECRET=84dac9e %curl -H "ClientId: $CLIENT_ID" -H "ClientSecret: $CLIENT_SECRET" http://secret.com %curl -H "ClientId: $CLIENT_ID" -H "ClientSecret: $CLIENT_SECRET" -XPOST http://secret.com/reset
Chowamy klucze w zmiennych środowiskowych. Pierwsze dwa polecenia zaczynamy od spacji, przez co Zsh (w typowej konfiguracji) nie zachowa polecenia w historii. Do historii trafią 2 różne wywołania curla, które wyglądają trochę bardziej czytelnie przez pominięcie długich kluczy.
Problemy: wszystko przepada po zamknięciu terminala. Jeśli następnego dnia musimy kontynuować pracę, trzeba od nowa ustawić każdą zmienną środowiskową. Wpisywanie 7 poleceń, żeby móc zacząć pracę, nie jest wygodne.
Zaraz opiszę, jak można próbować to naprawić, a teraz szybkie wyjaśnienie, czemu takie podejście, a nie inne.
Dlaczego zmienne środowiskowe
W artykule będę używał jednego sposobu przechowywania parametrów: w zmiennych środowiskowych (environment variables). Czemu?
Java Properties (typu -Dclient.id=client1) działają, wiadomo, tylko w Javie. Przekazywanie jest kłopotliwe: musimy dokleić je do polecenia java, co nie zawsze jest łatwe, bo na przykład to, co odpalamy, jest napisane w Javie, ale ma shellowy skrypt startowy. Często żeby ustawić jakiś parametr, trzeba edytować jakiś plik . Jeśli plik jest pod kontrolą wersji, trzeba pamiętać, żeby nie poszedł do commita. Jeśli nie jest, powstaje problem, żeby nie zapomnieć przywrócić stan przed zmianami (i nie pomylić się robiąc to ręcznie).
IntelliJ ma opcję edycji 'Run/Debug Configurations’, gdzie można wpisać jakie tylko chcemy parametry. Jest to dobre rozwiązanie, ale ma też wady: trzeba dużo klikać, trzeba jeszcze więcej klikać jeśli chcemy mieć zestaw parametrów używany nie tylko w jednym „tasku”, ale w kilku. Oraz, wiadomo, działa tylko wewnątrz IDE.
Zmiennych środowiskowych nie trzeba „przepychać” ręcznie do celu i działają niezależnie od „platformy”. Propagują się same, czyli ustawiamy je w sesji terminala, odpalamy curla i curl widzi zmienne środowiskowe, potem z tego samego terminala odpalamy Javę i program napisany w Javie też widzi te same zmienne środowiskowe.
Spring Boot ma konwencję, jak ustawiać parametry ze zmiennych środowiskowych. Gdy w kodzie mamy @Value("${some.client.id}"), ustawiamy zmienną środowiskową SOME_CLIENT_ID – i tak dalej. Oznacza to, że wszystko da się osiągnąć ustawiając tylko zmienne środowiskowe, bez edytowania jakichkolwiek plików. Zmienne znikają, wraca standardowe zachowanie, nie trzeba żadnego git reset, nie ma obawy, że wrzucimy do Gita parametry używane tylko na potrzeby zadania w danym dniu.
Kolejna zaleta – używanie do lokalnego developmentu tych samych mechanizmów, co na środowisku produkcyjnym. Bardzo często „na produkcji” klucze i inne parametry wstrzykuje się do kontenera Dockera właśnie przez zmienne środowiskowe. Możemy popatrzeć, jakie zmienne środowiskowe są ustawione tam, i ustawić takie same u siebie lokalnie.
Sprytniej, ale nie do końca
Ostatnie z omawianych rozwiązań (ustawienie zmiennych środowiskowych w konsoli) było całkiem w porządku, ale wadą było, że jeśli wyłączyliśmy laptopa, to po jego włączeniu trzeba było trochę ręcznej pracy, żeby ustawić z powrotem wszystkie environment variables na swoim miejscu.
Da się zmienne środowiskowe zachować? Da się. Można na przykład wpisać je do ~/.zshrc:
alias ll='ls -alF' # itp. itd. export CLIENT_ID=client1
Albo jeszcze lepiej: wpisać je zamiast tego do ~/.zshenv, wtedy będą widoczne zarówno w terminalu, jak i w IntelliJ (wyjaśnienie czemu – na StackExchange).
Są jednak problemy. Mamy tajne klucze przydzielone tylko na potrzeby jednego zadania i potem powinniśmy przestać z nich korzystać. Będziesz pamiętać, żeby potem wrócić do edytowanego pliku i skasować z niego dopisane klucze?
Drugi problem: zrobiliśmy z naszych tajnych kluczy zmienne globalne. Każdy proces ma do nich dostęp. Odpalamy frontend napisany w NodeJS, a tam znowu ktoś wrogo przejął jakąś paczkę NPM-a, i ta jedna paczka śle na dalekie serwery wszystkie dostępne zmienne środowiskowe. Nasze tajne klucze wyciekły.
Pliki .env
W tym miejscu pojawia się pomysł plików .env. Czyli coś takiego, co robiliśmy z ~/.zshenv, ale ograniczone do jednego projektu, żeby zły NodeJS nie położył łapy na naszych tajnych kluczach potrzebnych tylko w Javie. Składnia podobna, ale bez export:
CLIENT_ID=client1 CLIENT_SECRET=84dac9e
Jeśli plik jest jeden, umieszczamy go w katalogu głównym projektu i nazywamy .env:
% ls -a -1 .editorconfig .env .git .gitignore gradlew gradlew.bat
Możemy też mieć kilka plików, na przykład plik na środowisko albo typ zadania.
Nie mieszamy różnych rzeczy (jak dodając klucze do własnego ~/.zshenv). Mamy mały plik, w którym są tylko parametry pod jedno konkretne użycie w projekcie. Po skończonej pracy możemy go po prostu skasować. Albo nawet zautomatyzować usunięcie, na przykład poleceniem at: echo "rm .env" | at now + 2 days).
Pliki .env są bardziej popularne w innych ekosystemach (np. we frontendzie). Biblioteki wprowadzające obsługę takich plików zazwyczaj zawierają „dotenv” w nazwie. W Javie obsługa wymaga trochę wiedzy.
IntelliJ
Nic nie zadziała samo – potrzebujemy pluginu EnvFile.
Obsługę pliku .env trzeba włączyć osobno dla każdego run configuration. Tu przykład mojej konfiguracji dla testu odpalanego przez Gradle’a:
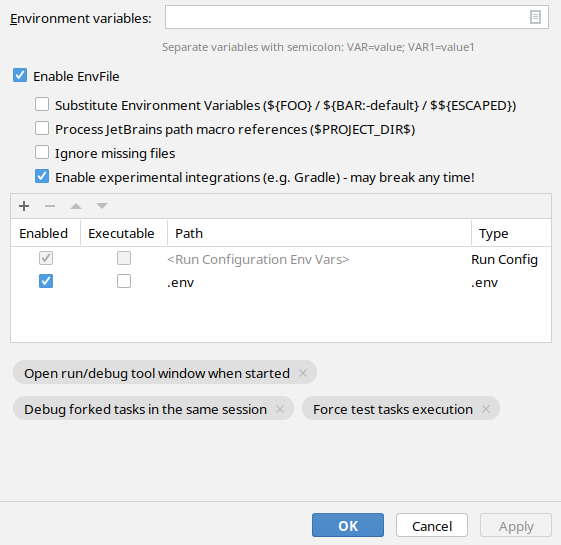
Więcej dokumentacji można znaleźć na GitHubie.
Konsola
Wydawało by się, że plik .env to prawie że skrypt i łatwo będzie użyć go z terminala. Nic z tego – składnia jest ok, ale brakuje export, więc nie dostaniemy nic:
source .env echo $CLIENT_ID # pusto
Konieczna jest sztuczka: włączenie allexport podczas importu:
set -a; source .env; set +a echo $CLIENT_ID # ok!
Podsumowanie
Pliki .env pozwalają na łatwe zarządzanie zestawem parametrów potrzebnych w jednym konkretnym projekcie, do jednego konkretnego zadania. Unikamy udostępniania tajnych kluczy w globalnych zmiennych widocznych dla każdego procesu. Mamy jedno jasne, widoczne miejsce przechowywania tajnych danych, które nigdzie nie są kopiowane. Łatwiej zarządzać jednym plikiem (aktualizować klucze albo usunąć całość) niż sprzątać parametry poukrywane gdzieś w zakamarkach IDE.